CodeOrion:从代码图到 Agentic 代码审计
AI Agent 对代码审计的影响正在变得越来越明显。
过去做白盒审计时,工具更多是先通过规则、污点分析、数据流分析或代码图查询发现疑似问题,再由安全人员继续确认入口、参数来源、调用链、过滤逻辑、依赖版本和可利用条件。这个流程长期有效,但也有一个现实问题:真正判断一个漏洞是否成立,往往不只看某个危险函数是否被调用,而是要把代码上下文、框架行为、业务逻辑、第三方依赖和验证结果串成一条完整证据链。
AI Agent 的出现,让这件事有了新的可能。它不只是帮人解释一条扫描告警,也不只是把源码总结成自然语言,而是可以像审计员一样持续追问:这个接口是否外部可达?参数是否来自用户输入?中间有没有鉴权、校验或清洗?调用是否进入第三方组件?组件内部是否存在敏感逻辑?这个风险能不能构造请求验证?最终结论有没有证据支撑?
但这也带来一个新的问题:如果直接把大量源码丢给 Agent,让它凭上下文自由推理,它很容易受到上下文窗口、幻觉、路径遗漏和过早下结论的影响。代码审计不能只依赖模型直觉,它需要稳定、可查询、可复核的结构化事实。
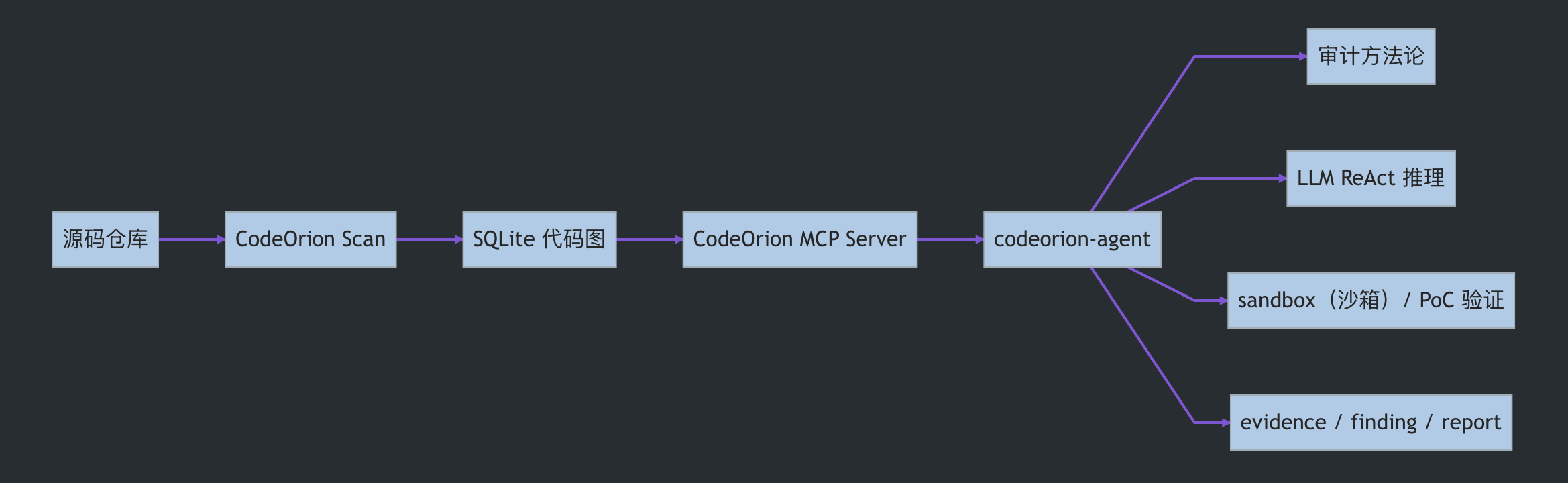
这也是我做 CodeOrion 的原因。CodeOrion 不是想再做一个传统规则扫描器,而是想探索一种更适合 AI Agent 的代码审计底座:先把源码、符号、入口、调用关系和依赖边界整理成代码图,再让 Agent 基于这些事实进行查询、推理、取证和验证。换句话说,CodeOrion 负责把代码变成 Agent 能可靠使用的结构事实,codeorion-agent 负责把这些事实组织成审计证据链。
传统白盒代码扫描已经发展了很多年。CodeQL、Semgrep、Joern 这类工具证明了一件事:代码不能只被当成文本扫描,必须被还原成结构。
Joern 的 Code Property Graph 把程序表示成带属性的有向图,并把语法结构、控制流、数据流放到统一的图模型中查询。CodeQL 和 Semgrep 的数据流、污点分析也都离不开 source(输入来源)、propagator(传播规则)、sanitizer(过滤逻辑)和 sink(危险操作)这些基础模型。
这些方向都非常重要。但我在真实代码审计里遇到的问题是:只靠静态规则和固定建模,往往很难以低成本走完整条漏洞判断链路,尤其是跨框架、跨文件、跨依赖和需要业务上下文时。
传统工具可以通过数据流、污点分析和图查询回答一部分问题,但这些能力高度依赖 source、sink、sanitizer、框架和依赖模型的完整度。真实项目里,剩下的大量判断仍然需要上下文推理和证据验证:
- 这个 sink(危险调用)是否真的能从 HTTP 入口到达?
- 参数是否来自用户输入?
- 中间有没有鉴权、校验、清洗、格式约束?
- 风险是否藏在第三方组件内部?
- 这个 finding(风险结论)是否能构造出可复现请求?
- 报告里的结论是否有可追溯证据?
所以我做 CodeOrion 时,没有把它设计成“又一个规则扫描器”。我更希望它成为一个面向 AI Agent 的代码图底座:CodeOrion 负责把代码变成可查询的结构事实,codeorion-agent 负责基于这些事实完成审计推理、evidence(证据)登记、finding(风险结论)输出和 PoC 验证。
一、白盒扫描正在从“规则命中”走向“图谱、证据和 Agent”
在写 CodeOrion 之前,我先看的是白盒代码审计工具过去十几年的演进路线。这个领域并不是从 LLM 出现后才开始做自动化,相反,SAST、数据流分析、污点分析、代码属性图、软件成分分析都已经积累了很长时间。
如果把这条路线压缩成几个阶段,大致是这样:

这条路线说明了一件事:白盒扫描的核心矛盾一直没有变。工具要尽可能覆盖全仓,又要尽可能减少误报;要足够自动化,又要理解复杂业务上下文;要能发现已知模式,又不能被规则库限制住。
1、Code Property Graph:代码图路线已经被长期验证
Code Property Graph 不是一个新概念。Joern 文档里把 CPG 定义为一种用于在大型代码库中挖掘编程模式的数据结构,它以节点、带标签的有向边、键值属性来表示程序构造。Joern 也明确提到,早期 CPG 工作的核心思想是把语法、控制流、过程内数据流等经典程序表示合并到一个属性图里,再通过图遍历 DSL 查询漏洞模式。
这对 CodeOrion 的启发很直接:如果要让 Agent 审计代码,不能只把源码切片塞给模型。源码文本太长、太散、太依赖局部上下文。更合理的方式是先把代码变成图,让 Agent 通过工具查询图。
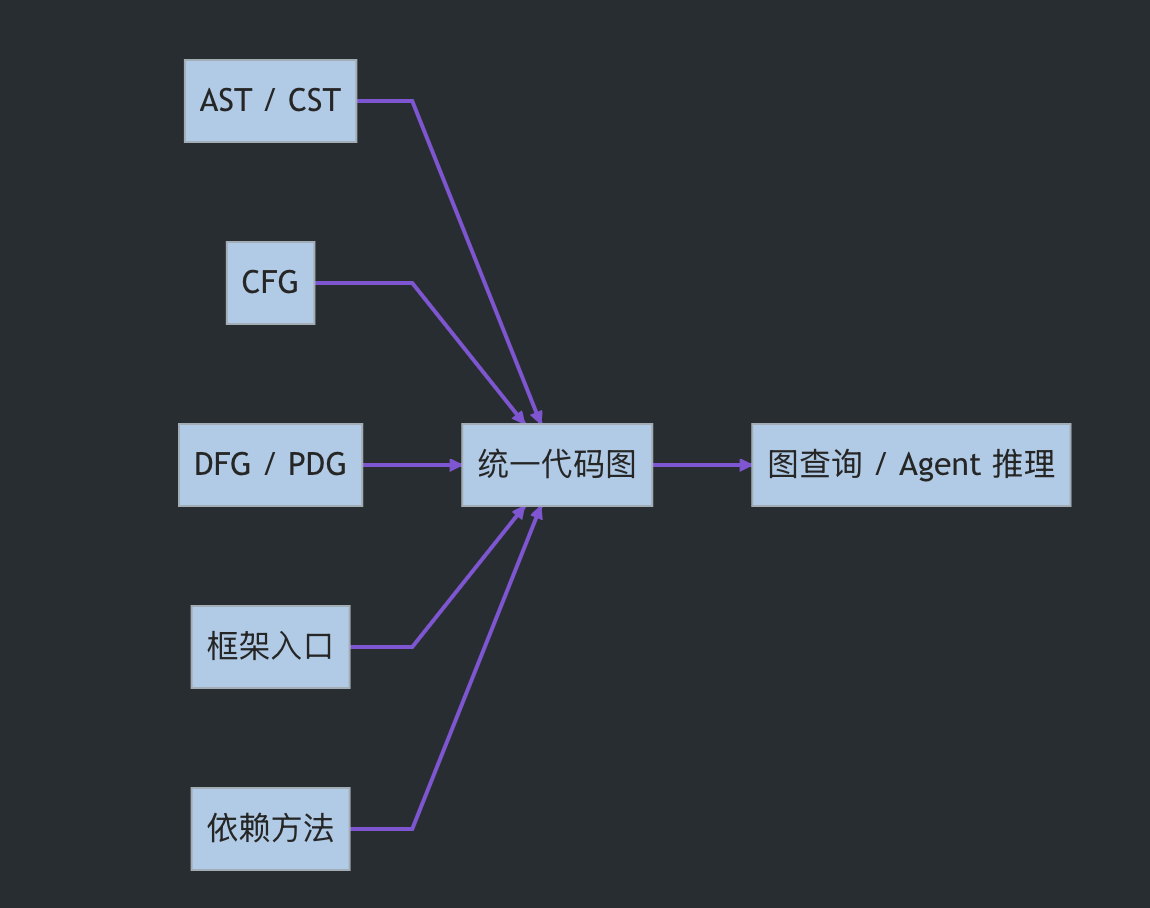
CodeOrion 和 Joern 的目标并不完全相同。Joern 更成熟地围绕 CPGQL、CPG schema 和多语言前端构建静态分析平台;CodeOrion 当前更聚焦在“面向 Agent 消费”的工程形态上:统一 IR、SQLite 存储、MCP 工具、自然语言查询、跨边界依赖追踪、证据输出。
换句话说,CodeOrion 当前不是完整意义上的 Joern CPG 实现,而是一个面向 Agent 消费的代码图底座。它借鉴 CPG 的统一图思想,但现阶段重点落在 CST、符号、框架入口、依赖边界和可查询证据上。
2、CodeQL 和 Semgrep 证明了 source / sink 模型的价值,也暴露了规则维护成本
CodeQL 的官方文档把数据流分析描述为计算变量在程序不同位置可能持有的值,以及这些值如何传播、在哪里使用。很多安全查询都依赖数据流分析,用来判断潜在恶意或不安全数据是否以危险方式被使用。CodeQL 也区分普通数据流和污点传播:前者关注值是否保持,后者关注值是否受到不安全输入影响。
Semgrep 的污点模式则更直观。一个污点规则需要定义 source(输入来源)、propagator(传播方式)、sanitizer(过滤逻辑)和 sink(危险操作)。Semgrep 文档里也提到,污点会从 source 经过赋值和函数调用传播到 sink;如果中间没有被 sanitizer 处理,就会报告 finding。
这套模型很强,但它天然依赖建模质量:
- source 要覆盖所有入口
- sink 要覆盖所有敏感 API
- sanitizer 要避免过度信任或过度怀疑
- propagator 要理解框架、库、容器对象、ORM、模板引擎
- 跨函数、跨文件分析要在准确率和性能之间取舍
Semgrep 文档里还提到,跨文件分析需要更多内存资源,实际效果依赖语言和规则配置。CodeQL 文档也明确列出数据流图完整性挑战:标准库源码不可见、运行时行为不确定、别名问题、全局数据流图巨大且计算昂贵。
这说明传统规则和污点分析不是“不好”,而是它们在复杂业务项目里需要大量工程建模。CodeOrion 的思路不是抛弃这些能力,而是把 source、sink、sanitizer 从“命中即漏洞”的最终判定降级为“候选事实”和“审计线索”,再由 Agent 结合调用链、数据流证据、框架入口、依赖路径、配置和验证结果进行二次判断。
3、SCA 解决了组件可见性,但还不等于组件风险可达性
OWASP Top 10:2021 把 Vulnerable and Outdated Components 放在 A06。OWASP 的描述很清楚:如果不知道自己使用的所有组件版本,包括直接依赖和嵌套依赖,就很可能处于风险中;组织应该持续 inventory 组件版本,使用 OWASP Dependency Check、retire.js、SCA 等工具自动化这个过程。
SCA 也要区分不同层次。比较基础的 SCA 通常主要看依赖清单、SBOM、包名和版本,输出“项目用了某个有漏洞的组件”。更进一步的 SCA 已经开始判断:漏洞相关方法是否真的被应用调用路径触达。
但“方法可达”仍然不是最终风险结论。
真实审计还要继续问:
- 这个漏洞对应的方法是否被项目调用?
- 从外部入口是否能到达这个方法?
- 项目使用方式是否满足漏洞触发条件?
- 是否存在配置、参数、Feature、版本分支上的限制?
- 这个组件是否被 shading、clone、重命名或隐藏依赖绕过普通 SBOM 识别?
近几年的 SCA 研究也在往这个方向走。比如漏洞方法分析关注的就是“漏洞方法是否从应用执行路径可达”,而不是只看组件版本。关于 SBOM 和 SCA 的研究也指出,隐藏依赖、组件变体、代码克隆、依赖重打包会导致漏洞报告不一致或漏报。
CodeOrion 的 dependency_callgraph 和 trace_dependency_calls 就是沿着这个方向做的:我不只想知道项目依赖了什么,更想把项目调用点、依赖方法、依赖内部调用链和 Agent 证据验证串起来。
4、LLM Agent 正在进入告警研判,但不能只做“告警解释器”
2025 到 2026 年,LLM 结合 SAST 的研究明显增多。很多工作关注 false positive reduction(误报过滤):先让传统 SAST 产出候选告警,再让 LLM 或多 Agent 根据代码上下文判断哪些告警更可信。
例如 QASecClaw 这类多 Agent SAST 误报过滤研究,把传统 SAST 和代码专用 LLM 结合起来,由不同 Agent 负责测试规划、安全验证、证据关联、过滤和报告。另一些研究也在讨论 LLM Agent 对 CodeQL、Semgrep 等工具告警进行 triage(告警研判)的能力。
这些研究说明 LLM Agent 正在进入 SAST 的告警研判和验证环节,但整体仍处于快速探索阶段。现阶段更现实的路线不是让 LLM 替代静态分析,而是让 LLM 基于静态分析、代码图、证据和可控验证环境做辅助判断。
但我不希望 codeorion-agent 只是一个“告警解释器”。如果流程是:
SAST 先吐告警 -> LLM 再解释告警那 LLM 仍然被传统规则的召回边界限制住。CodeOrion 的路线更接近:
代码图提供结构事实 -> Agent 自己选择入口、路径、依赖、数据流、证据 -> 输出风险结论这就是 CodeOrion 和 codeorion-agent 组合的关键差异:Agent 不是站在告警后面做客服,而是站在代码图前面做审计员。
二、传统白盒扫描的几个痛点
我把传统 SAST 的问题分成三类。
1、规则硬编码问题
大部分 SAST 的底层逻辑依然离不开规则:哪些函数是 source(输入来源),哪些函数是 sink(危险操作),哪些调用算 sanitizer(过滤逻辑),哪些赋值和函数调用算 propagator(传播规则)。规则是必要的,但规则越多,维护成本越高。框架、组件、业务封装稍微变化,规则就可能失效、漏报或误报。
例如同样是 SQL 注入,在真实项目里可能经过 Controller 参数绑定、DTO 转换、Service 封装、动态查询构造、ORM wrapper、XML mapper、注解 SQL、分页插件、租户插件。单独写一个 “字符串拼接 SQL” 规则,很容易只能覆盖最表层的样例。
2、上下文不足问题
静态分析要准确理解数据流,本身就很难。标准库源码不可见、运行时分派不确定、别名关系复杂、全局数据流计算成本高,这些都是长期存在的问题。真实业务项目还会叠加框架路由、依赖注入、权限中间件、配置文件、消息队列、异步任务等上下文。
这会导致很多扫描结果停在“疑似”。它命中了 source 和 sink,但没有证明入口是否可达,也没有证明中间是否经过 sanitizer,更没有说明这个漏洞在业务语义上是否真的成立。
3、组件风险深入困难
现代应用大量风险不在业务代码的最后一行,而在“业务代码如何调用组件”。反序列化、模板渲染、表达式执行、文件解析、服务端请求、ORM 拼接、日志组件、鉴权框架,这些问题经常藏在第三方依赖的使用方式里。
传统扫描如果只看到项目源码,很容易停在“用了某个包”或“调用了某个 API”。但安全审计真正需要的是:从外部入口到项目调用点,再到依赖方法,再到依赖内部危险行为,这条链路是否成立。
三、CodeOrion 的定位:不直接判漏洞,而是提供结构事实
CodeOrion 的核心定位是多语言代码图系统。它基于 Tree-sitter 把源代码解析成统一 IR,构建 CST 图、框架端点图、依赖调用图,并存入 SQLite。CodeOrion 核心引擎不做“命中即漏洞”的最终判定,而是提供可解释、可查询、可组合的结构事实;漏洞判断由 codeorion-agent 结合 Skill、图查询、源码证据和验证结果完成。
我希望 CodeOrion 回答的是这些基础问题:
- 项目里有哪些文件、类、函数、调用点?
- 哪些位置是 HTTP 入口?
- 某个符号的调用者和被调用者是谁?
- 某个入口能否到达某个危险 API?
- 某个项目调用点是否解析到第三方依赖方法?
- 从项目代码能否继续追进依赖内部调用链?
整体扫描链路如下:
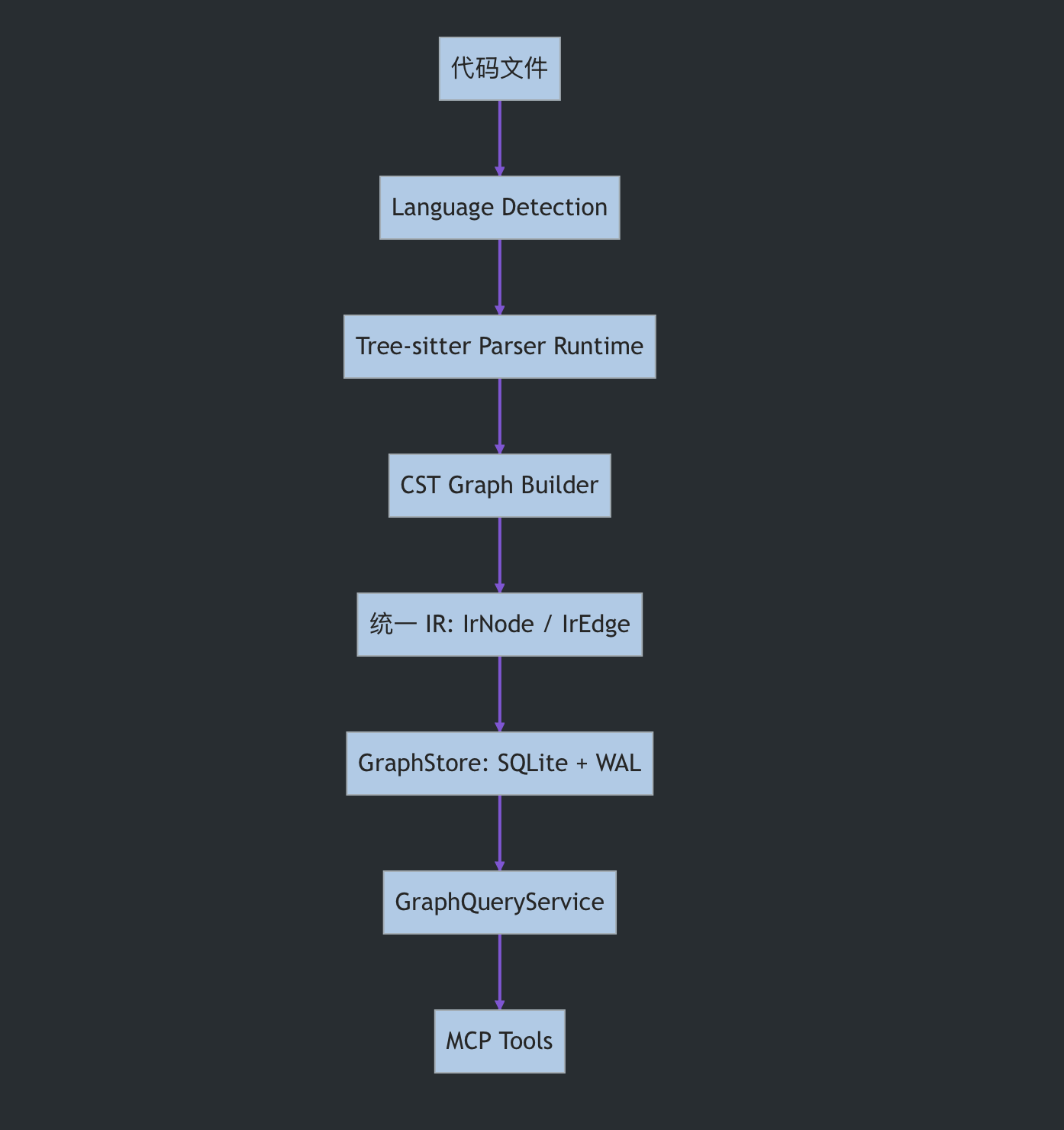
当前 CodeOrion 的主扫描流程包括:
- Grammar Registry 注册语言 Grammar
- LanguageDetector 识别文件语言
- ParserRuntime 调用 Tree-sitter 解析源码
- CstGraphBuilder 把 CST 转成统一 IR 节点和边
- GraphStore 把节点、边、诊断、符号信息写入 SQLite
- 可选启用
--framework-facts提取 HTTP 入口 - 可选启用
--dependency-callgraph展开依赖和跨边界调用
这里最关键的不是“扫描出一个告警”,而是把源码变成 Agent 可以反复检索的图谱。
一个传统规则扫描器通常输出的是结论:
发现危险函数 Runtime.exec
疑似命令执行CodeOrion 更关注过程事实:
POST /api/task/run
-> TaskController.run
-> TaskService.execute
-> CommandRunner.run
-> Runtime.exec这条链路比单点命中更接近真实审计的工作方式。
四、MCP:让代码图成为 Agent 的工具
代码图本身不是最终产品。真正有价值的是,Agent 能不能低成本地查询它、组合它、验证它。
CodeOrion 通过 FastMCP 暴露图查询能力。Agent 可以通过 MCP 工具完成项目扫描、符号搜索、入口枚举、调用图遍历、数据流追踪、依赖分析和自然语言探索。
其中我最看重的是 trace_dependency_calls。它支持从 HTTP 入口、项目方法或依赖方法出发,做正向或反向追踪。

这解决的是传统 SAST / SCA 在真实项目里成本较高的问题:组件不是只看“有没有依赖”,而是要看“项目是否调用了相关依赖方法、调用链是否从外部入口可达、用户输入是否真的流向危险参数、可利用条件是否满足”。
例如某个 Java 项目使用了 Fastjson。传统依赖扫描可能告诉我“这个版本存在历史风险”,传统代码扫描可能告诉我“这里调用了 parseObject”。但真正的白盒审计还要继续问:
- 这个 parseObject 是否接收外部输入?
- 从哪个 HTTP 入口进入?
- 中间是否限制了类型、字段或 Feature?
- 是否调用到了危险反序列化路径?
- 这个调用是否在真实业务路径里可达?
CodeOrion 的依赖追踪不是为了替代人工判断,而是把这些问题变成可查询的图路径。
五、更理想化的目标:从业务漏洞走向组件 0day 风险链路
我做 CodeOrion 和 codeorion-agent,还有一个更理想化的目标:传统静态代码审计通常更关注“业务代码本身是否写出了漏洞”,但真实攻击面并不只存在于业务代码。
有时候业务代码本身确实存在漏洞,例如把用户输入直接拼接 SQL、直接传给命令执行、直接传给反序列化 API。这个场景传统 SAST、污点分析、人工审计都比较熟悉。
但还有另一类更难的问题:业务代码看起来没有明显漏洞,甚至代码写法在当时的公开知识里是“正常调用”,但它调用的第三方组件内部存在一个非公开 0day,或者存在一个只有在特定参数、特定配置、特定版本、特定运行环境下才触发的深层缺陷。这时真正的问题就变成:
- 外部输入能否到达这个组件方法?
- 业务代码是否把高危数据类型、表达式、模板、URL、文件名、对象 key、序列化数据传给组件?
- 组件内部是否继续进入解析器、解释器、反射、类加载、模板渲染、网络请求、文件系统等敏感逻辑?
- 如果未来披露一个组件 0day,我能否快速回答“我的哪些业务入口暴露在这条路径上”?
- 即使 0day 尚未公开,我能否基于组件内部调用链发现异常复杂、异常危险、异常暴露的风险路径?
这不是说 CodeOrion 能凭空“发现所有 0day”。这句话必须讲清楚。0day 的本质是未知缺陷,任何工具都不应该宣称可以自动完整发现。但 CodeOrion 想做的是把组件风险分析从“有没有这个依赖”推进到“业务入口如何调用这个依赖、用户输入如何进入组件、组件内部走向哪些敏感逻辑”。
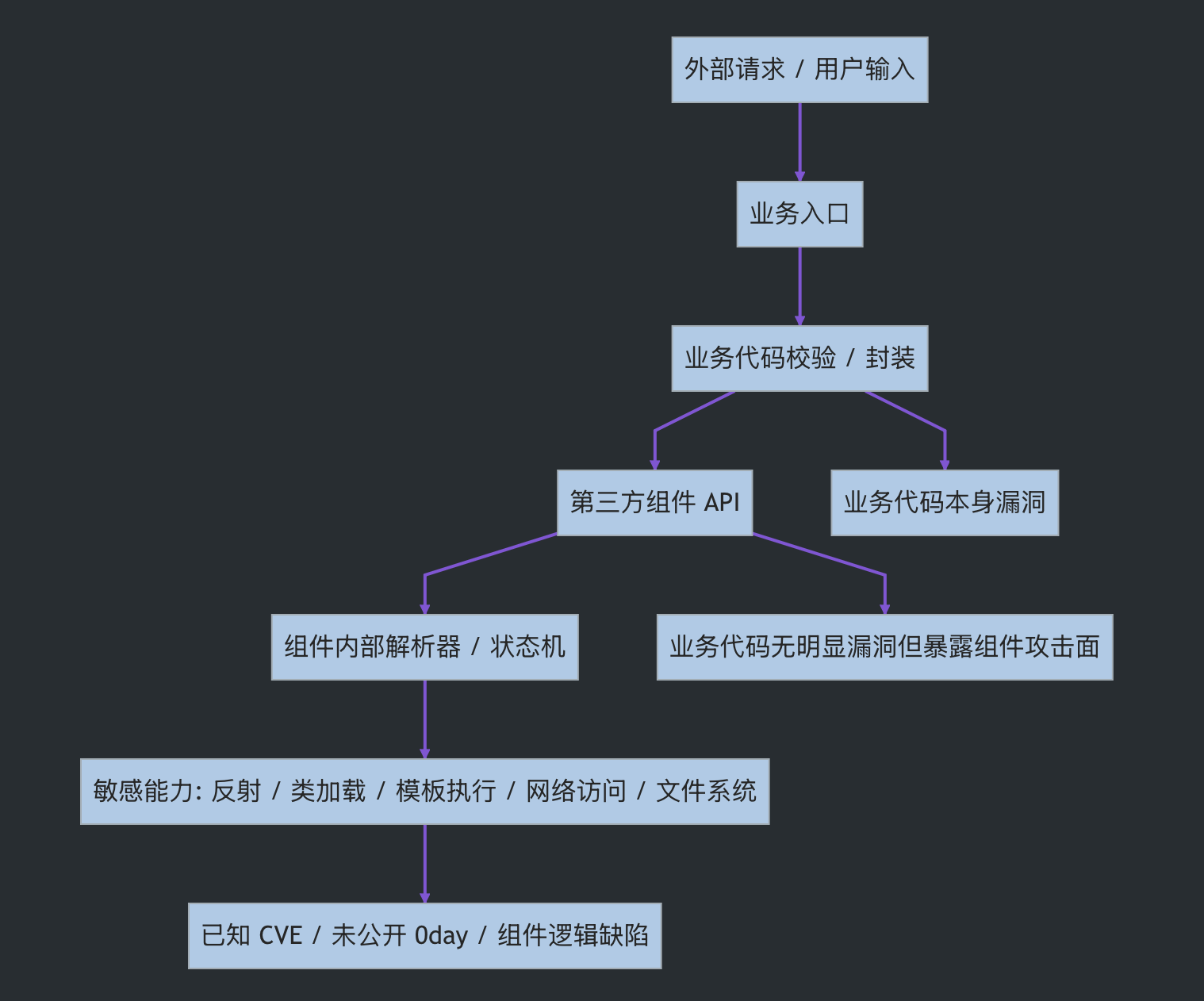
从审计视角看,这里其实有两条线:
| 场景 | 传统关注点 | CodeOrion 更想补的部分 |
|---|---|---|
| 业务代码本身有漏洞 | 确认用户输入是否进入危险 API | 用代码图和 Agent 把入口、数据流、调用链、证据、PoC 串起来 |
| 业务代码本身无明显漏洞,但调用了高风险组件 | 组件版本、公开 CVE、是否使用危险 API | 追踪业务入口到组件方法,再继续观察组件内部是否进入解析、反射、类加载、模板、网络、文件等敏感路径 |
| 组件存在非公开 0day | 传统工具通常没有规则或 CVE 可匹配 | 先回答可达性和影响范围:哪些入口、参数、调用点、组件方法可能受影响 |
这种能力在真实安全运营里很有价值。
当某个组件 0day 刚被披露时,很多团队第一反应是查 SBOM 或 Maven / npm / PyPI / Go module 版本,看“我有没有用这个包”。但这只是第一步。更关键的问题是:
我是否调用了漏洞相关方法?
这个调用是否从外部入口可达?
用户输入是否进入了关键参数?
有没有配置或运行条件让漏洞触发?
影响哪些接口、哪些业务、哪些租户?CodeOrion 的理想路径是:

如果 0day 尚未公开,CodeOrion 也可以做更偏研究型的组件风险挖掘:从业务入口出发,找那些“外部可控输入进入复杂组件解析器”的路径,再让 Agent 结合 Skill 做人工可复核的风险排序。例如:
- 外部 JSON 进入反序列化组件
- 外部模板进入模板引擎
- 外部 URL 进入 HTTP client / cloud SDK
- 外部文件名进入压缩包、图片、Office、PDF、XML 解析器
- 外部表达式进入规则引擎、脚本引擎、SpEL、OGNL、MVEL
- 外部对象 key 进入对象存储 SDK
这类路径不一定马上就是漏洞,但它们是高价值审计入口。传统 SAST 更擅长在业务代码里寻找已知模式;CodeOrion 更希望把“业务代码 + 第三方组件 + 组件内部敏感逻辑”的路径暴露出来,让 Agent 和人工审计员能围绕这些路径做更深入的验证。
所以我对 CodeOrion 的长期想法不是“再写一套规则库”,而是做一个面向漏洞研究和安全审计的代码图雷达:
已知漏洞:快速确认是否使用、是否可达、影响面多大
未知漏洞:找出外部输入进入复杂组件敏感逻辑的候选路径
验证阶段:把候选路径变成审计证据、风险结论、PoC 或待复核项这件事比较理想化,也一定需要长期工程投入。它依赖更强的依赖方法展开、更好的框架建模、更准确的数据流、更丰富的组件风险知识库,以及 Agent 与人工审计员之间更好的协作。但我认为这是 CodeOrion 最值得做的方向之一。
六、一个具体例子:Fastjson 反序列化链路可以怎么追
这里用 Fastjson 举一个更具体的例子。
假设项目里有一个接口:
@PostMapping("/fastjson/deserialize")
public Object deserialize(@RequestBody String params) {
return JSON.parseObject(params);
}传统扫描器通常能看到两类信息。
第一,依赖扫描会告诉我项目用了 com.alibaba:fastjson:1.2.x,这个版本可能存在历史反序列化风险。
第二,代码扫描会告诉我业务代码里调用了 JSON.parseObject(params),而 params 可能来自 HTTP body。
但这还不够。因为我真正关心的是完整风险路径:
外部 HTTP 请求
-> Controller 参数绑定
-> JSON.parseObject(params)
-> fastjson 依赖方法
-> DefaultJSONParser
-> ParserConfig / JavaBeanDeserializer / TypeUtils
-> 可能进入类型解析、类加载或反序列化敏感逻辑这里必须强调一个边界:调用到 parseObject 或类型解析路径,只代表风险候选,不等于漏洞成立。Fastjson 是否可利用仍然取决于版本、AutoType、safeMode、Feature、目标类型、gadget、JDK、黑白名单和运行环境。
白盒审计里至少要分三层:
| 层级 | 说明 | 是否等于漏洞 |
|---|---|---|
| 调用链可达 | A 函数能调用到 B 函数 | 不等于 |
| 数据流可达 | 用户输入能传播到危险参数 | 还不一定 |
| 可利用条件满足 | 版本、配置、参数、gadget、权限和环境都满足 | 才接近漏洞成立 |
CodeOrion 追这条链路时,会分成几个阶段。
1、扫描项目并打开框架入口和依赖调用图
我会让 CodeOrion 扫描项目,同时启用框架事实和依赖调用图:
codeorion scan --path . \
--framework-facts \
--dependency-callgraph \
--dependency-source-mode auto \
--dependency-depth 10这里发生了几件事:
--framework-facts会把 Spring MVC 的@PostMapping("/fastjson/deserialize")提取成 HTTP 入口节点--dependency-callgraph会解析 Maven / Gradle 依赖,识别com.alibaba:fastjson- JVM 侧车会按需分析被项目调用触达的 fastjson artifact
- 项目调用点会通过
resolves_to_dependency_method边连接到依赖方法 - fastjson 内部方法会以
dependency_method节点和calls边进入同一个图
这一步的关键是“按需展开”。我不需要一开始把所有依赖全量反编译到爆炸,而是先从项目中出现的外部调用目标出发,例如 com.alibaba.fastjson.JSON.parseObject,再去展开相关 artifact。
2、从 HTTP 入口开始追踪
扫描完成后,Agent 可以通过 MCP 先拿入口:
codeorion_get_endpoints()它会看到类似这样的入口:
POST /fastjson/deserialize
handler: FastJsonController.deserialize
framework: spring_mvc然后从这个 HTTP 入口正向追踪:
codeorion_trace_dependency_calls(
http_method="POST",
route="/fastjson/deserialize",
max_hops=12,
include_project=true,
include_dependency=true
)期望得到的链路不是一句“发现 parseObject”,而是一组可解释的调用路径步骤:
POST /fastjson/deserialize [HTTP 入口]
-> FastJsonController.deserialize(String params) [project]
-> JSON.parseObject(params) [项目调用点]
-> com.alibaba.fastjson.JSON.parseObject(String, Class, ...) [dependency_method]
-> DefaultJSONParser.parseObject(Type) [dependency_method]
-> ParserConfig.getDeserializer(Type) [dependency_method]
-> JavaBeanDeserializer.deserialze(...) [dependency_method]
-> TypeUtils.loadClass(String, ...) [dependency_method]这条追踪结果的含义是:从 HTTP 入口到 fastjson 相关依赖方法存在调用路径。它还不能单独证明反序列化漏洞成立。接下来 Agent 必须继续检查数据流和利用条件:
- 用户输入是否真的进入
JSON.parseObject的 JSON 字符串参数 - 是否存在
@type或等价类型控制点进入反序列化逻辑 - 是否启用了 AutoType 或绕过了限制
- 是否存在
ParserConfig.getGlobalInstance().setAutoTypeSupport(true) - 是否使用了危险 Feature
- 是否升级到了安全版本或启用了 safeMode
- 是否存在黑白名单配置
- 当前 JDK、gadget、依赖版本和运行环境是否满足触发条件
用图表示就是:
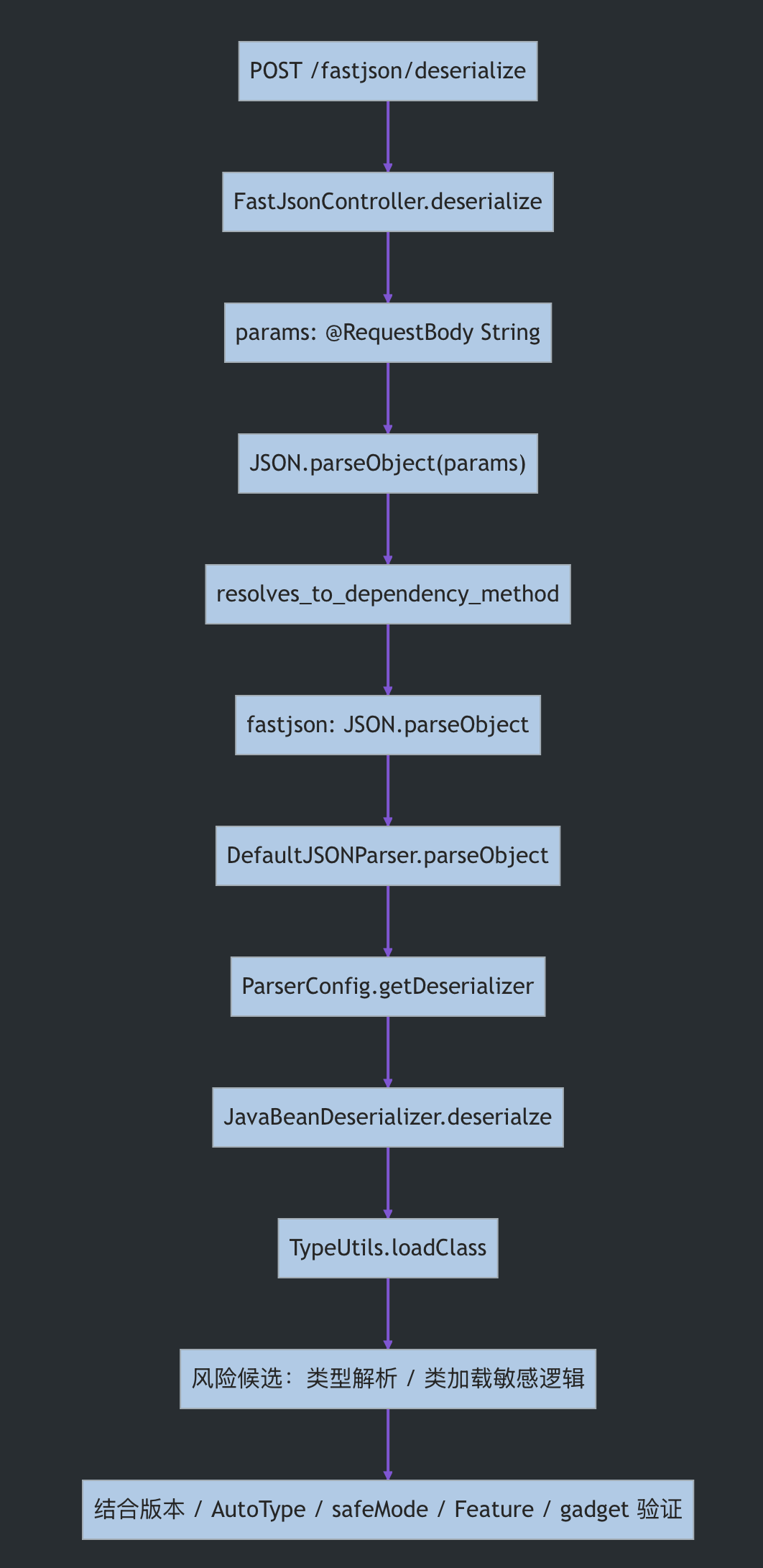
这张图里,前半段是业务代码可达性,中间是用户输入到依赖方法的路径,后半段是组件内部风险候选和利用条件验证。基础的 SCA 常常告诉我“fastjson 版本有风险”,传统规则扫描常常告诉我“parseObject 被调用”。CodeOrion 想补齐的是中间这条可查询、可复核的证据路径。
3、从依赖方法反向追踪谁在用它
Fastjson 这种组件风险还有一个常见审计方式:不是从 HTTP 入口正向追,而是先从依赖危险方法反向问“谁在调用它”。
Agent 可以先搜索依赖方法:
codeorion_search_dependency_methods(method_name="parseObject")找到 com.alibaba.fastjson.JSON.parseObject 后,再反向追踪:
codeorion_trace_dependency_calls(
start_node_id="<dependency_method_node_id>",
direction="backward",
max_hops=12
)这样可以得到:
com.alibaba.fastjson.JSON.parseObject
<- JSON.parseObject(params)
<- FastJsonController.deserialize
<- POST /fastjson/deserialize这个能力适合做组件风险排查。比如我想知道项目里所有 Fastjson、Jackson、SnakeYAML、XStream、ObjectInputStream、JNDI、表达式引擎相关入口,不需要先猜每个 Controller,而是可以从依赖方法或危险 API 反推业务入口。反向追踪仍然只是候选收敛手段,后续还要继续确认用户输入、配置条件和可利用性。
4、Agent 不是直接报漏洞,而是登记证据
追到链路之后,codeorion-agent 还不会直接写“存在漏洞”。它会继续把 MCP 结果登记成证据:
register_evidence(
summary="POST /fastjson/deserialize 到 JSON.parseObject 的跨依赖调用链",
mcp_tools=["codeorion_trace_dependency_calls"],
entrypoint_id="<endpoint_node_id>",
sink_symbol_id="<dependency_method_node_id>"
)然后再输出风险结论:
emit_finding(
vuln_type="deserialization",
title="Fastjson parseObject 接收外部 JSON 导致反序列化风险",
input_entry={file, line, route, parameter},
dangerous_method={dependency_coordinate, method},
dataflow_path=[
"HTTP body 进入 params",
"params 传入 JSON.parseObject",
"跨边界进入 fastjson JSON.parseObject",
"进入 DefaultJSONParser / TypeUtils.loadClass"
],
evidence_refs=["ev-..."],
raw_request="POST /fastjson/deserialize HTTP/1.1 ..."
)这里的 dataflow_path 不能只写“函数调用到了哪里”,还要写清楚用户输入如何进入危险参数。如果只能证明调用链,结论应该标成候选或待复核;只有数据流和利用条件都有证据时,才应提升为确认。
最后,如果目标环境可运行,再由验证子 Agent 或沙箱去验证 PoC。这样一条 Fastjson 风险结论最终包含三类证据:
- 入口证据:HTTP 入口和参数来源
- 路径证据:项目调用点到依赖内部方法的追踪结果
- 条件证据:版本、AutoType、safeMode、Feature、gadget、JDK 和黑白名单
- 验证证据:原始请求、沙箱响应、人工复核结论
这就是我想表达的“追得深”:不是只看到 JSON.parseObject,也不是把调用链直接当成漏洞,而是把入口、项目调用、依赖边界、数据流、组件内部风险候选、利用条件和证据落盘串起来。
七、Python 和 Go 的组件依赖怎么做
Fastjson 是 Java 生态的例子。Java 的优势是 Maven / Gradle 坐标明确,JAR 可通过 JVM 侧车做字节码分析,SootUp 可以提供 Jimple、CHA、RTA、Qilin 等不同精度的调用图模式。
但 CodeOrion 不是只为 Java 写的。Python 和 Go 的依赖处理方式不一样,因为它们的包管理、源码分发和调用模型都不同。
1、Python:从 requirements / pyproject 到 site-packages 源码展开
Python 项目常见依赖来源包括:
requirements.txtpyproject.tomlsetup.cfgsetup.py- 当前虚拟环境的
site-packages
CodeOrion 的 Python 依赖解析会先生成 BuildManifest,识别 PyPI 包、版本和本地路径。对于被项目调用链触达的包,会在 site-packages 中定位包目录,然后按需解析源码。
解析策略是:

举一个 Python 反序列化例子:
from flask import request
import yaml
@app.post("/load")
def load():
data = request.data
return yaml.load(data, Loader=yaml.Loader)传统规则会提示 yaml.load 危险。CodeOrion 更希望追出:
POST /load
-> Flask handler load()
-> request.data
-> yaml.load(data, Loader=yaml.Loader)
-> dependency_method: yaml.load
-> PyYAML constructor / loader 内部路径再比如:
import pickle
def restore(blob):
return pickle.loads(blob)Agent 可以从 pickle.loads 反向追踪谁传入了外部 blob,也可以从 HTTP route 正向追踪到 pickle.loads。
Python 的难点在于动态性更强:运行时替换、动态导入、装饰器、框架魔法、运行时对象类型都可能影响精度。所以 Python 侧的策略不是声称“静态全精确”,而是尽量把依赖包源码、函数节点、调用边、入口参数和证据组织起来,让 Agent 能继续读关键源码和做验证。
2、Go:从 go.mod 到 GOMODCACHE,按需展开模块函数
Go 的依赖入口相对清晰,核心是:
go.modgo.sumgo.workreplace$GOMODCACHE
CodeOrion 的 Go 依赖解析会读取 go.mod,处理 require、replace、indirect,再从 $GOMODCACHE/pkg/mod 定位模块源码。对于命中的依赖函数,会按需展开模块中的导出函数和方法,并生成 dependency_module、dependency_function、dependency_method 节点。
Go 侧有三级降级策略:
- Level 1:tree-sitter-go,完整解析和调用链追踪
- Level 2:go/parser 子进程,提取导出符号签名
- Level 3:轻量符号提取,仅保留导出函数名等基础可见性,不参与高置信漏洞判断
流程可以画成:
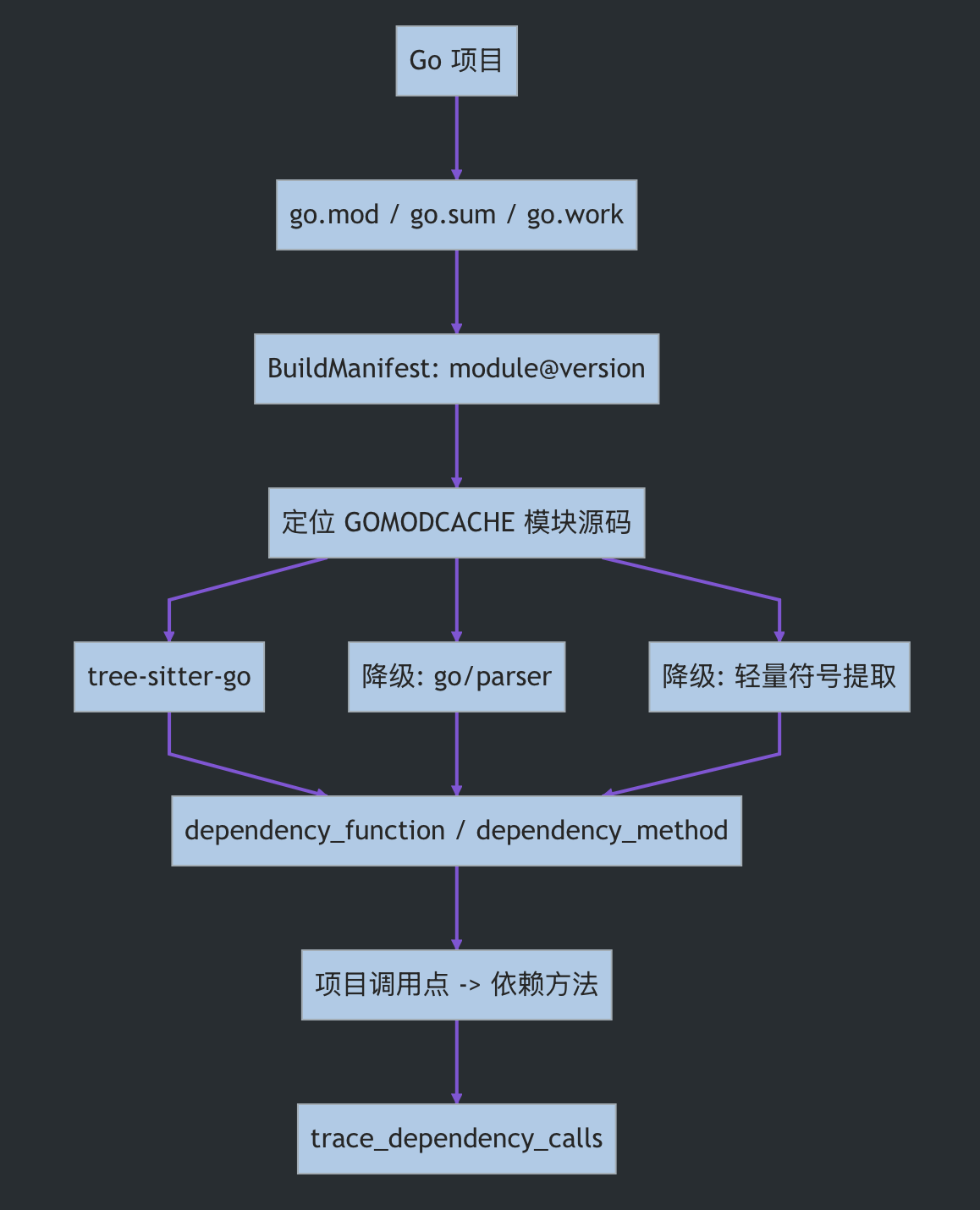
举一个 Go SSRF 风险例子:
func Fetch(c *gin.Context) {
target := c.Query("url")
resp, err := http.Get(target)
...
}CodeOrion 希望追出的不是“发现 http.Get”,而是:
GET /fetch?url=...
-> gin handler Fetch
-> c.Query("url")
-> http.Get(target)
-> dependency_method: net/http.Get
-> Client.Get
-> DefaultClient.Do再比如 Go 项目调用第三方 SDK:
client := storage.NewClient(...)
client.Download(ctx, userControlledKey)CodeOrion 可以把 go.mod 中的 SDK 模块解析出来,定位 $GOMODCACHE 中的源码,尝试把项目调用点连接到 SDK 的 exported method,再让 Agent 判断是否存在路径穿越、对象存储越权、SSRF、任意文件读取或凭据泄露风险。
Go 的优势是模块和源码路径相对规范,劣势是接口动态分派、泛型、构建标签、平台文件选择、replace 本地模块都会影响静态精度。所以 Go 侧同样采用“结构事实 + 证据链 + 必要时源码兜底”的策略。
八、CodeOrion-Agent:把静态图谱变成审计闭环
如果 CodeOrion 是图谱底座,那么 codeorion-agent 就是审计运行时。
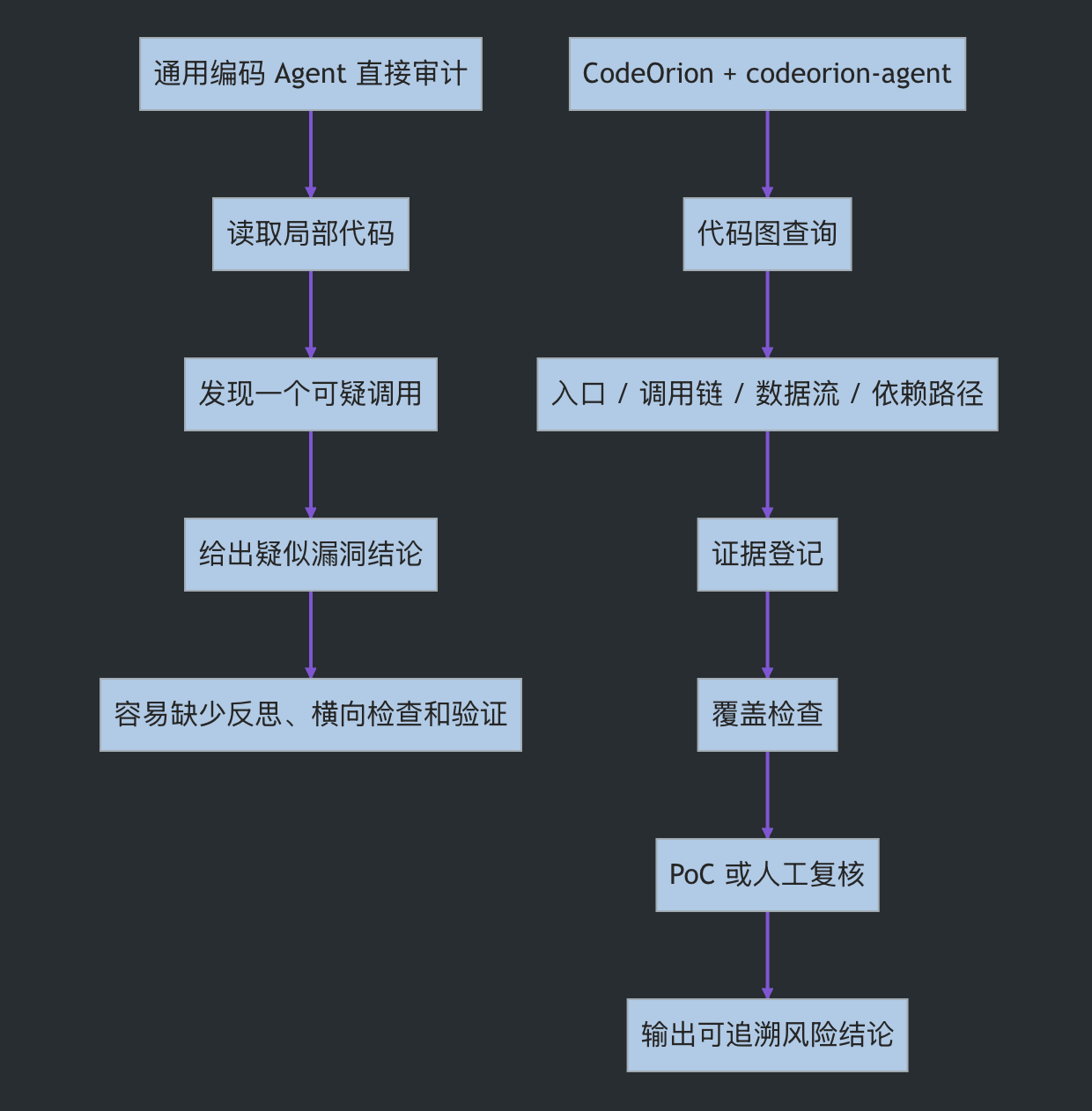
1、通用编码 Agent 做审计的问题
我在做这个项目前,也测试过直接使用 Claude Code、Cursor 这类通用编码 Agent 做代码审计。效果并不是完全不好。它们读代码、总结调用关系、发现一些明显危险写法时,确实经常能给出不错的结果。
但问题也很明显:在不做额外配置、不提供专门审计流程、不约束证据格式的情况下,通用编码 Agent 很容易跑几轮之后就停在一个“看起来像漏洞”的点上,然后直接给出结论。它不一定会继续追问:
- 这个入口是否真的外部可达?
- 参数是否真的来自用户输入?
- 中间有没有鉴权、校验、过滤或类型约束?
- 这个调用只是调用链可达,还是数据流也可达?
- 依赖组件的版本、配置、运行条件是否满足?
- 有没有相邻接口、相似分支、反向调用点需要一起检查?
- 这个漏洞能否构造 PoC,或者至少能否形成可复核证据?
这不是某一个工具的问题,而是通用编码 Agent 的默认目标不是“完成一次严格安全审计”。它更擅长在代码里完成编辑、解释、修复、重构;而白盒审计需要的是持续怀疑、反复回看、证据约束和验证闭环。
我希望 codeorion-agent 解决的正是这个问题:不让 Agent 只凭一次直觉下结论,而是把它放进一个更像安全审计员的工作流里。
2、Spring Cloud 跨服务调用追踪:一次探索和尝试
前面很多例子默认是单体应用:HTTP 入口、Controller、Service、DAO、组件调用都在同一个代码边界里。真实项目里,尤其是 Spring Cloud 微服务项目,一个外部请求经常会被网关、过滤器、Feign 客户端、WebClient、RestTemplate 和后端服务拆成多段。
这会带来一个很实际的问题:单个服务内的调用链看起来不危险,但跨服务串起来之后,风险才可能完整出现。

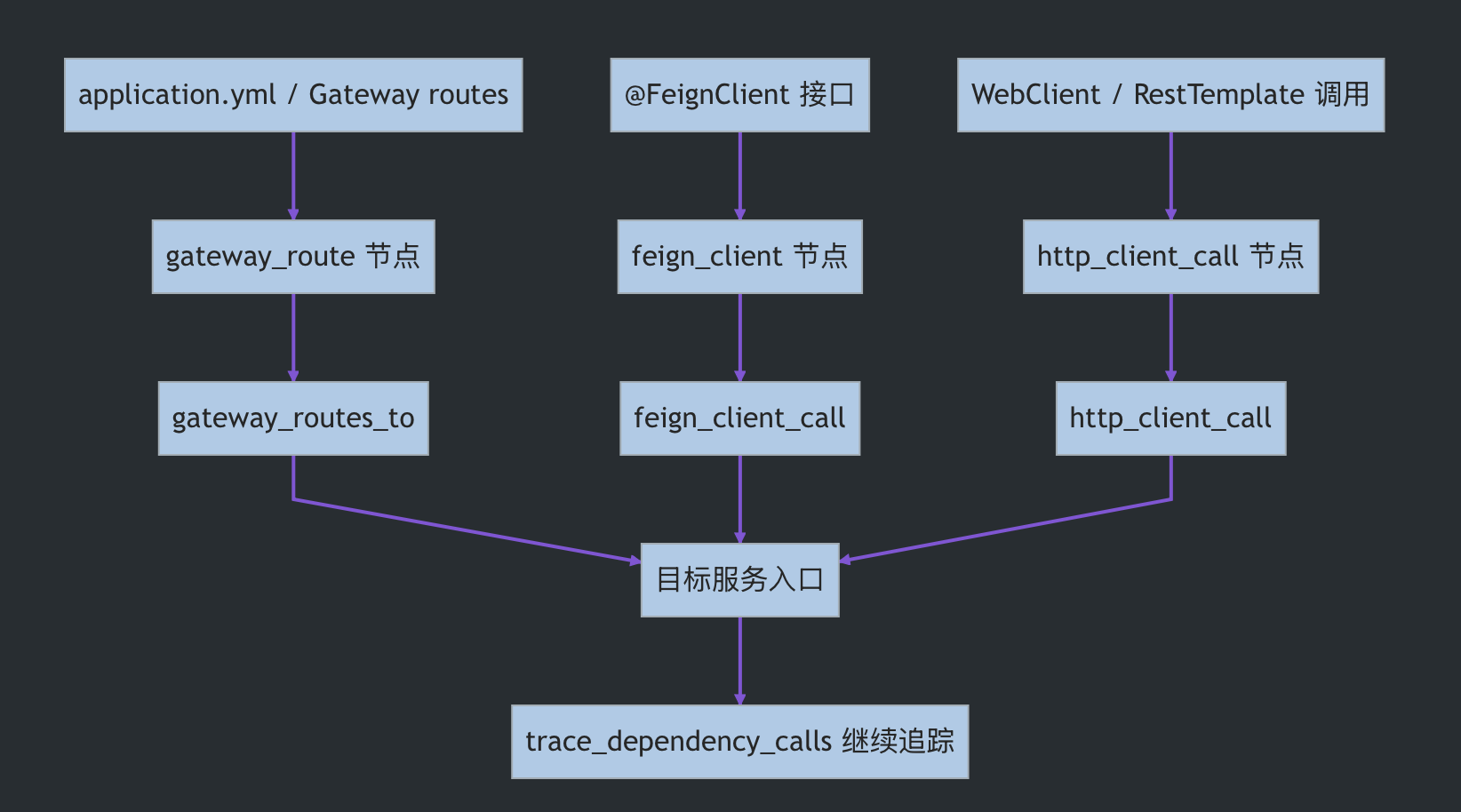
我在做 Spring Cloud 相关测试时,关注的不是“能不能扫到某个 Controller”,而是能不能先把一部分跨服务事实整理进代码图,让后续审计有路径可追:
| 跨服务模式 | 我尝试抽取的事实 | 写入图后的意义 |
|---|---|---|
| Spring Cloud Gateway | spring.cloud.gateway.routes 中的 Path 和 lb://serviceId |
知道外部路径会被路由到哪个后端服务 |
@FeignClient |
Feign 接口的 value / name、HTTP 方法和路径 |
知道服务间代理调用的目标服务和目标接口 |
WebClient / RestTemplate |
代码里的 HTTP URL、服务名、路径模板 | 知道过滤器、业务代码或 SDK 封装里发起了跨服务 HTTP 调用 |
| 调用追踪 | feign_client_call、http_client_call、gateway_routes_to 等边 |
Agent 可以尝试沿着图边从网关追到后端服务 |
以一个典型 Spring Cloud 项目为例,跨服务链路可能长这样:
GET /api/admin/users
-> Gateway route: /api/admin/** -> lb://ace-admin
-> ace-admin: AdminController.listUsers
-> UserService
-> UserMapper
-> DB也可能是过滤器或认证逻辑里的服务间调用:
Gateway Filter
-> WebClient.get("http://ace-admin/api/user/{username}/check_permission")
-> ace-admin: permission check endpoint
-> 权限查询 / token 校验 / 用户状态判断这类链路对安全审计很重要。很多权限绕过、认证缺陷、SSRF、日志注入、内部接口暴露,并不只存在于某一个服务的 Controller 里,而是藏在“网关如何转发”“过滤器如何调用认证服务”“业务服务如何调用内部服务”这些跨服务边界上。
CodeOrion 对 Spring Cloud 的探索仍然保持同一个原则:不直接判定漏洞,而是尝试把跨服务拓扑变成 Agent 可查询的结构事实。
这里也要讲清楚边界:这部分能力还处在探索和尝试阶段,首先解决的是“能不能把服务拓扑和调用候选路径纳入代码图”的问题,不等于已经完整解决微服务调用链追踪,更不等于自动证明漏洞成立。真正的漏洞判断仍然要继续确认请求参数、身份上下文、网关过滤器、服务间鉴权、配置、数据流和验证结果。
但这条路线说明,Spring Cloud 这类微服务架构并不是天然的白盒盲区。只要能把 Gateway 路由、Feign 接口、WebClient / RestTemplate 调用逐步整理成结构事实,Agent 就有机会从单服务审计扩展到跨服务候选路径审计:先找到可能的后端入口,再继续追业务代码、依赖组件和证据验证。
回到 codeorion-agent 本身,它不是“扫描后吐一堆告警”,而是把一次审计拆成一条可追踪的工作流:
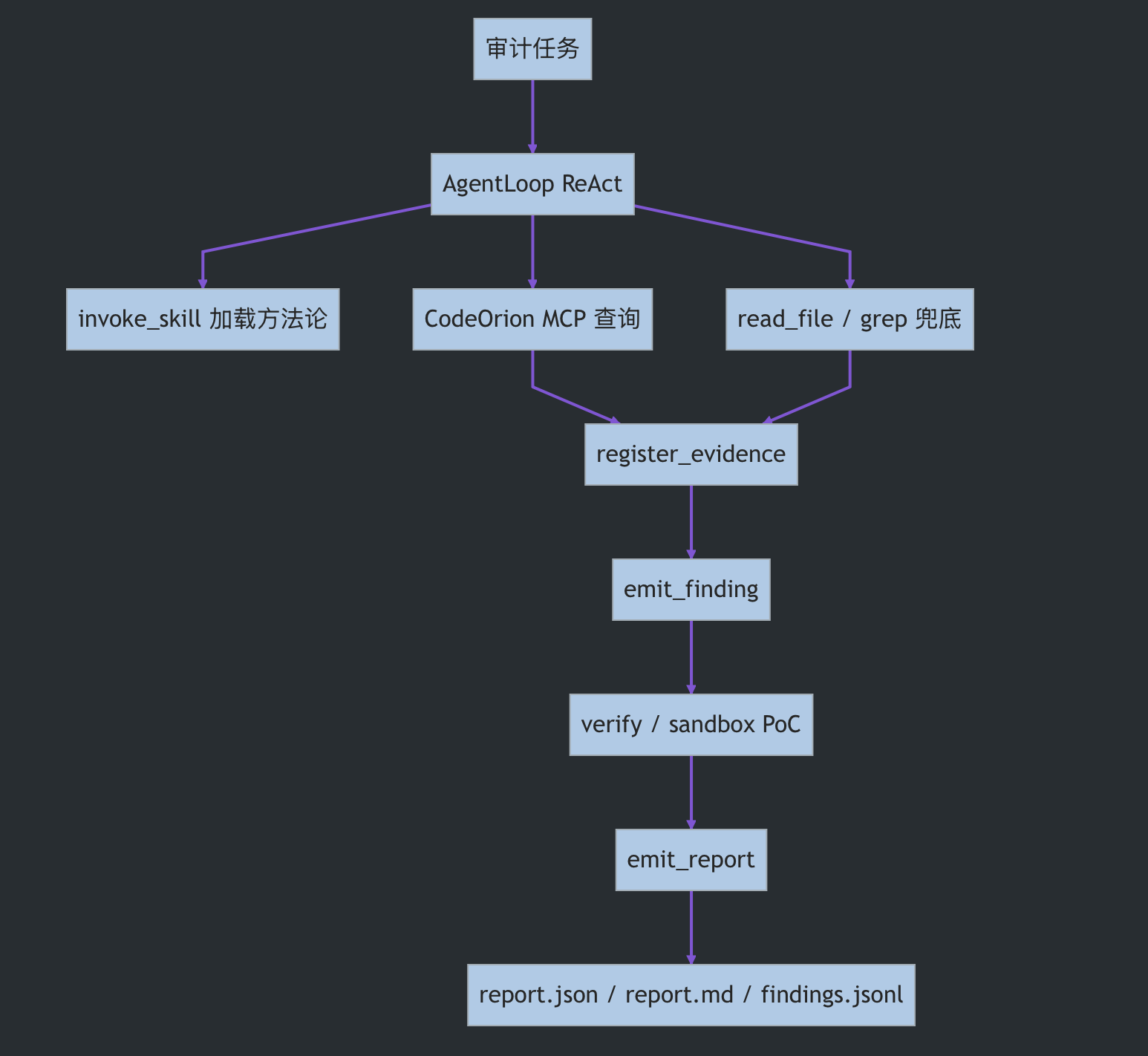
这张图对应的是 codeorion-agent 的整体审计闭环。下面几个设计,分别解决“怎么审”“证据怎么落地”“怎么验证”“怎么避免过早收敛”这几个问题。
3、审计方法论
审计不是只有规则,还需要方法论。
codeorion-agent 的 skills/ 目录按语言和漏洞类型组织审计方法,例如 Java SQL 注入、SSRF、IDOR、反序列化,Python 命令注入、路径穿越等。
Agent 可以先加载对应的审计方法论,再按方法论选择 MCP 工具。它不是盲目扫全仓,而是按漏洞类型组织探索路径:
入口点枚举
-> sink(危险操作)搜索
-> 调用链追踪
-> 数据流确认
-> sanitizer(过滤逻辑)检查
-> 依赖反向追溯
-> evidence(证据)登记
-> finding(风险结论)输出这让扫描从“规则命中”变成“审计流程”。
4、证据契约
我不希望 Agent 只是在报告里写“根据分析,这里存在漏洞”。
在 codeorion-agent 里,finding(风险结论)必须先有 evidence(证据)。Agent 需要调用 register_evidence 生成 ev-*,然后在 emit_finding 中引用这些证据。emit_finding 会校验证据是否真实存在。
也就是说,报告里的结论必须挂在具体工具结果上:
- MCP 返回的 HTTP 入口
- 调用链追踪结果
- 数据流追踪结果
- 文件路径和行号
- sandbox(沙箱)验证结果
- 原始 HTTP 请求
这个机制的目的很简单:减少 LLM 幻觉,让每个 finding 都能回溯到 evidence。
5、PoC 和验证
传统 SAST 的输出经常停在“疑似”。但在真实安全审计里,我更希望尽量走到“可复现”。
codeorion-agent 的 finding schema(风险结论结构)要求提供原始 HTTP 请求,并可以解析成 VerificationPoc。开启验证后,可以通过验证子 Agent、sandbox_http、sandbox_exec 进行 PoC 验证。
这一步并不保证所有漏洞都能自动验证,但它把审计从“静态判断”推进到了“验证优先”。
6、覆盖检查
Agent 很容易偷懒。比如找到一个明显 sink 后就结束,或者只看 Controller,不看依赖和配置。
所以 codeorion-agent 里有覆盖检查。它要求报告前必须覆盖入口追踪、横向检查、依赖反向追溯等内容,避免审计过程过早收敛。
这对真实审计很重要。因为漏洞不一定藏在最显眼的地方,很多关键风险来自鉴权遗漏、配置错误、二次注入、组件组合和业务状态机。
九、真实靶场验证:从审计到自动化 PoC
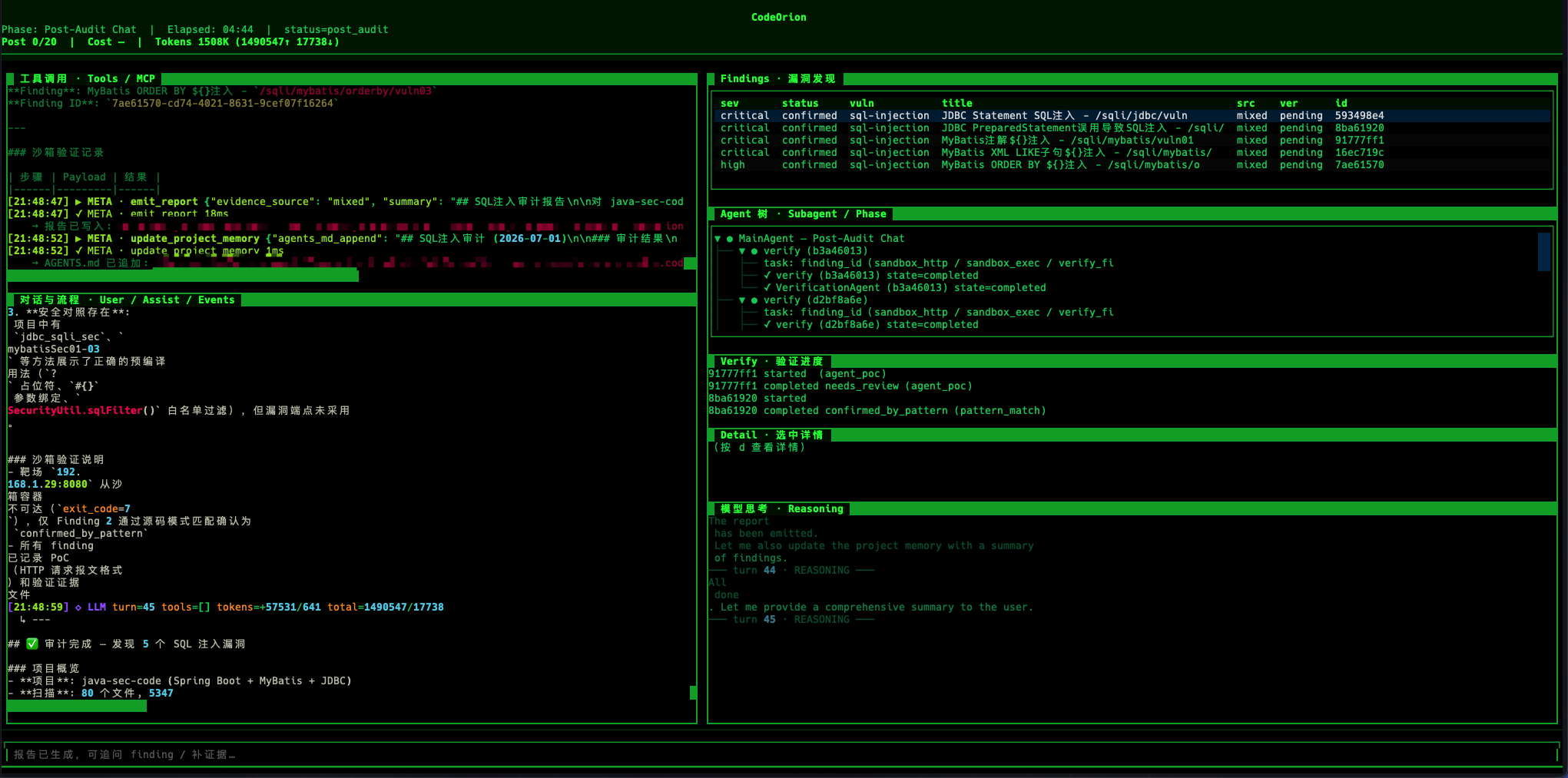
除了设计上的闭环,我还在 java-sec-code 靶场上跑过多轮真实验证。这个靶场里保留了完整的 run 产物,包括:
events.jsonltool_trace.jsonlfindings.jsonlevidence/ev-*.jsonevidence/ver-*.jsonsubagents/agent-*.jsonlreport/report.mdreport/report.json
这些产物能说明一件事:codeorion-agent 不是只输出静态结论,而是会把“审计过程”和“验证过程”都落盘。
1、一次 SQL 注入审计的完整产物
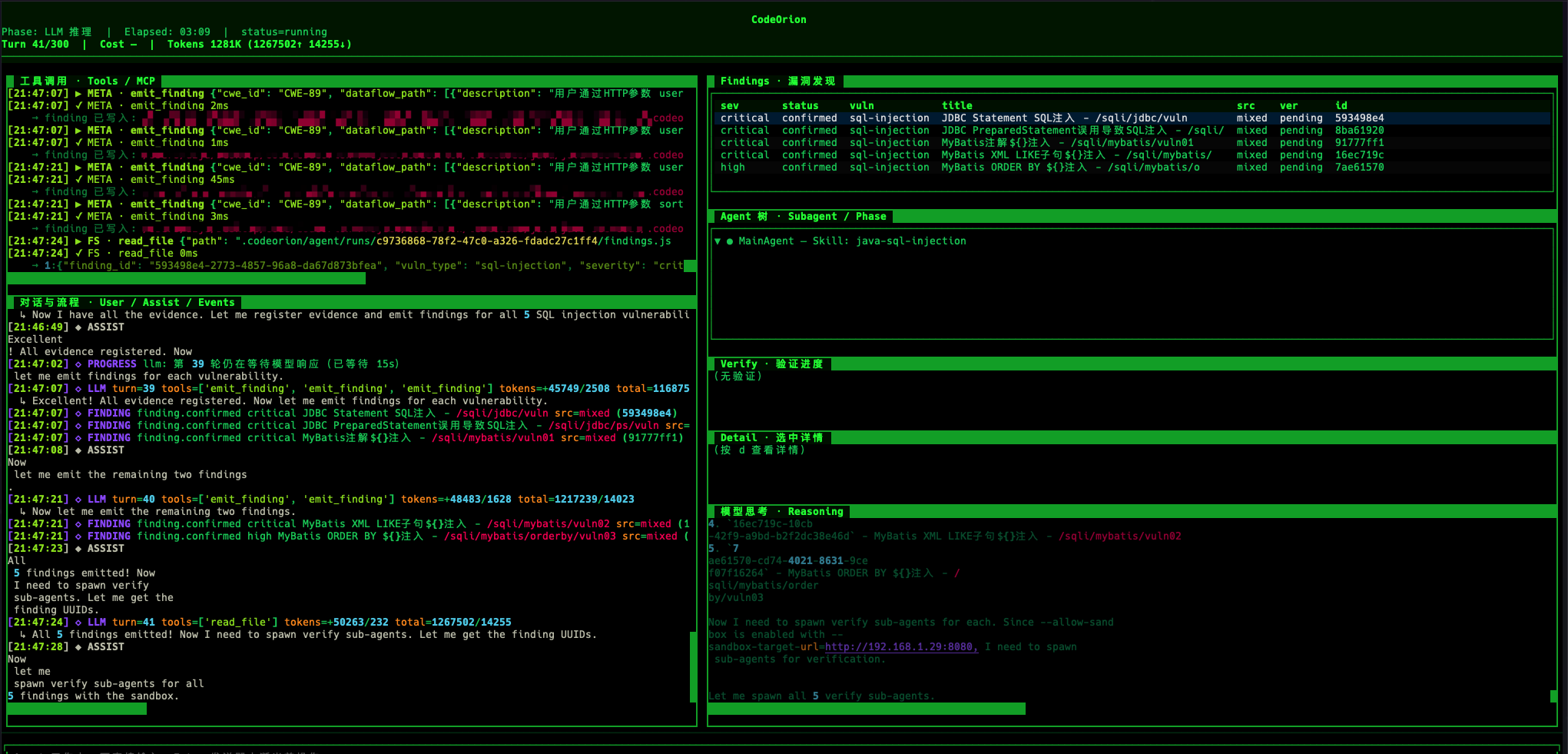
在 java-sec-code 的一次 SQL 注入审计 run 中,最终报告发现了 5 个 SQL 注入问题:
| 序号 | 端点 | 类型 | 验证状态 |
|---|---|---|---|
| 1 | /sqli/jdbc/vuln |
JDBC Statement 拼接 SQL | confirmed_by_pattern |
| 2 | /sqli/jdbc/ps/vuln |
PreparedStatement 误用,拼接后再 prepareStatement | confirmed_by_pattern |
| 3 | /sqli/mybatis/vuln01 |
MyBatis 注解 ${username} 直接替换 |
confirmed |
| 4 | /sqli/mybatis/vuln02 |
MyBatis XML LIKE ${_parameter} 直接替换 |
confirmed |
| 5 | /sqli/mybatis/orderby/vuln03 |
MyBatis XML ORDER BY ${order} 直接替换 |
confirmed |
这里最有意思的不是“发现了 5 个漏洞”,而是每条风险结论都带着审计证据和验证证据。
以 /sqli/jdbc/ps/vuln 为例,它看起来用了 PreparedStatement,但漏洞点在于 SQL 字符串已经提前拼接了用户输入:
String sql = "select * from users where username = '" + username + "'";
PreparedStatement st = con.prepareStatement(sql);这类问题很容易骗过只做关键字判断的工具:它看到 PreparedStatement 可能会误以为是安全写法。但 Agent 会继续检查 SQL 模板生成位置,发现用户输入在 prepareStatement() 之前已经进入 SQL 字符串。
审计链路可以抽象成:
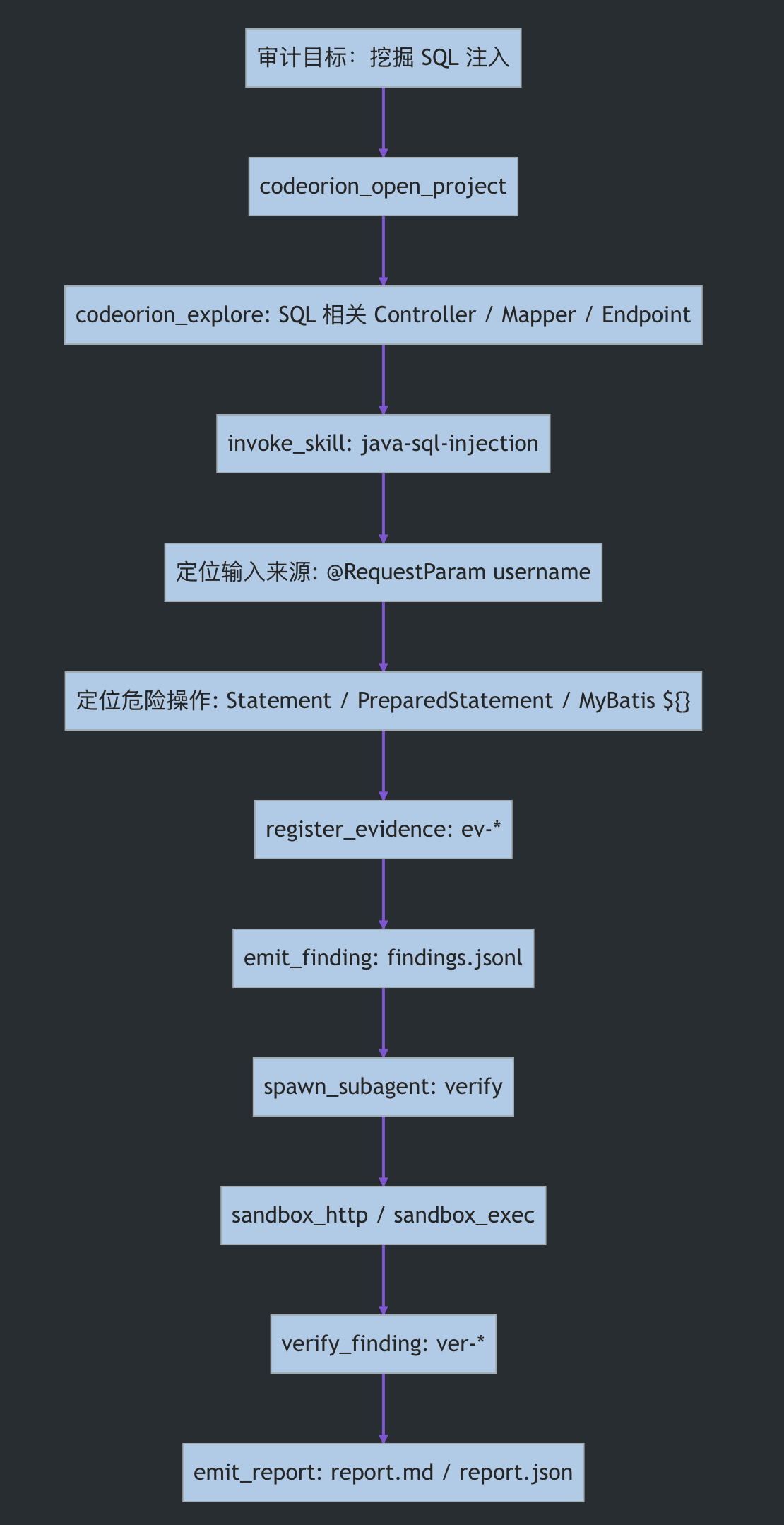
2、验证子 Agent 会自动处理登录、CSRF 和 Cookie
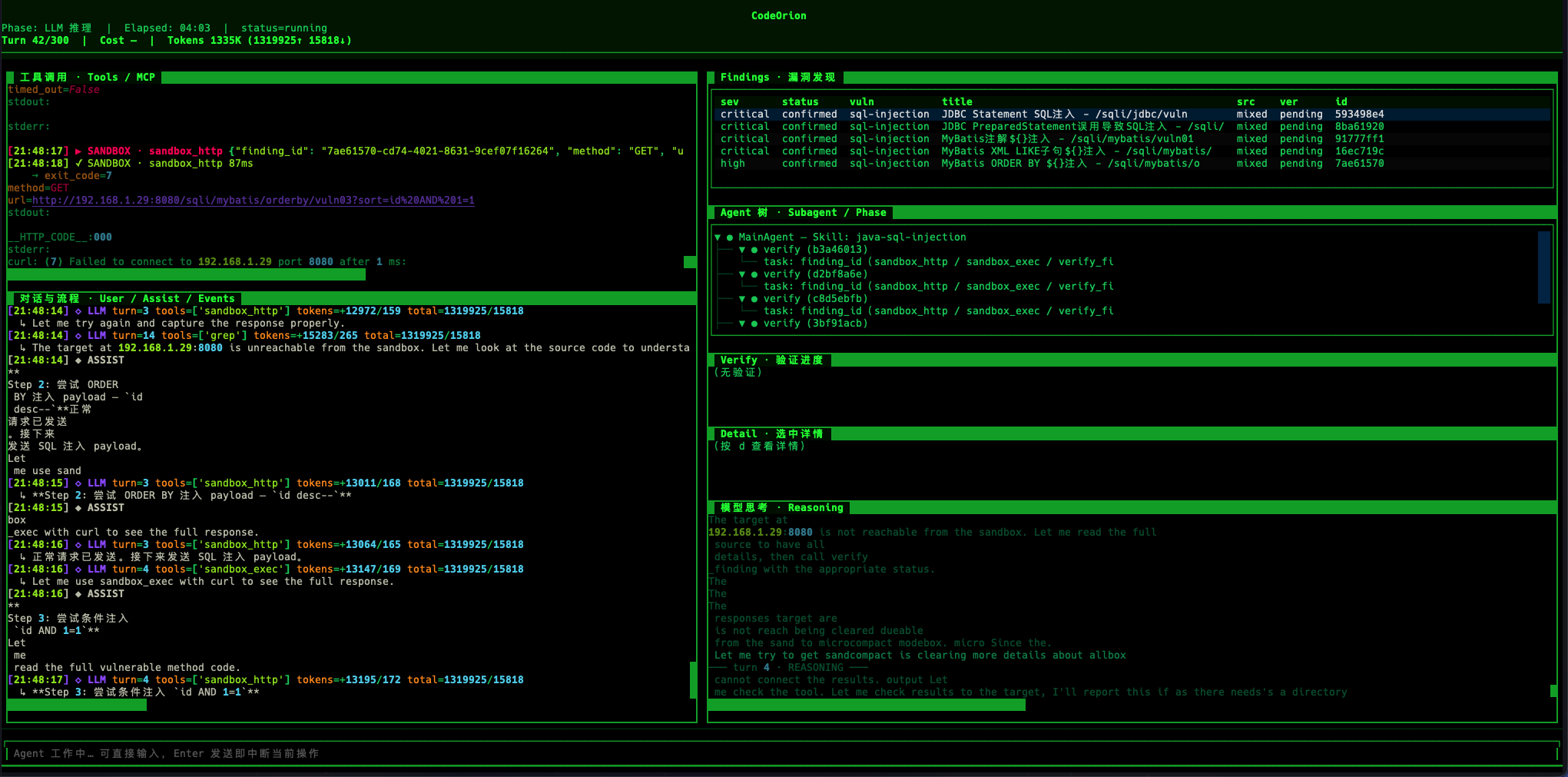
真实靶场并不是裸接口。很多端点访问前会跳转登录页,需要先拿 CSRF token,再登录,再带 Cookie 访问漏洞接口。
在 run 的 subagent 记录里,verify 子 Agent 做了这样的事情:
- 访问
/login获取登录页 - 从页面中提取
_csrf - 使用测试账号提交登录表单
- 保存 Cookie
- 携带 Cookie 请求漏洞接口
- 构造注入 payload
- 把响应摘要和 PoC 写入
ver-*.json
可以抽象成:
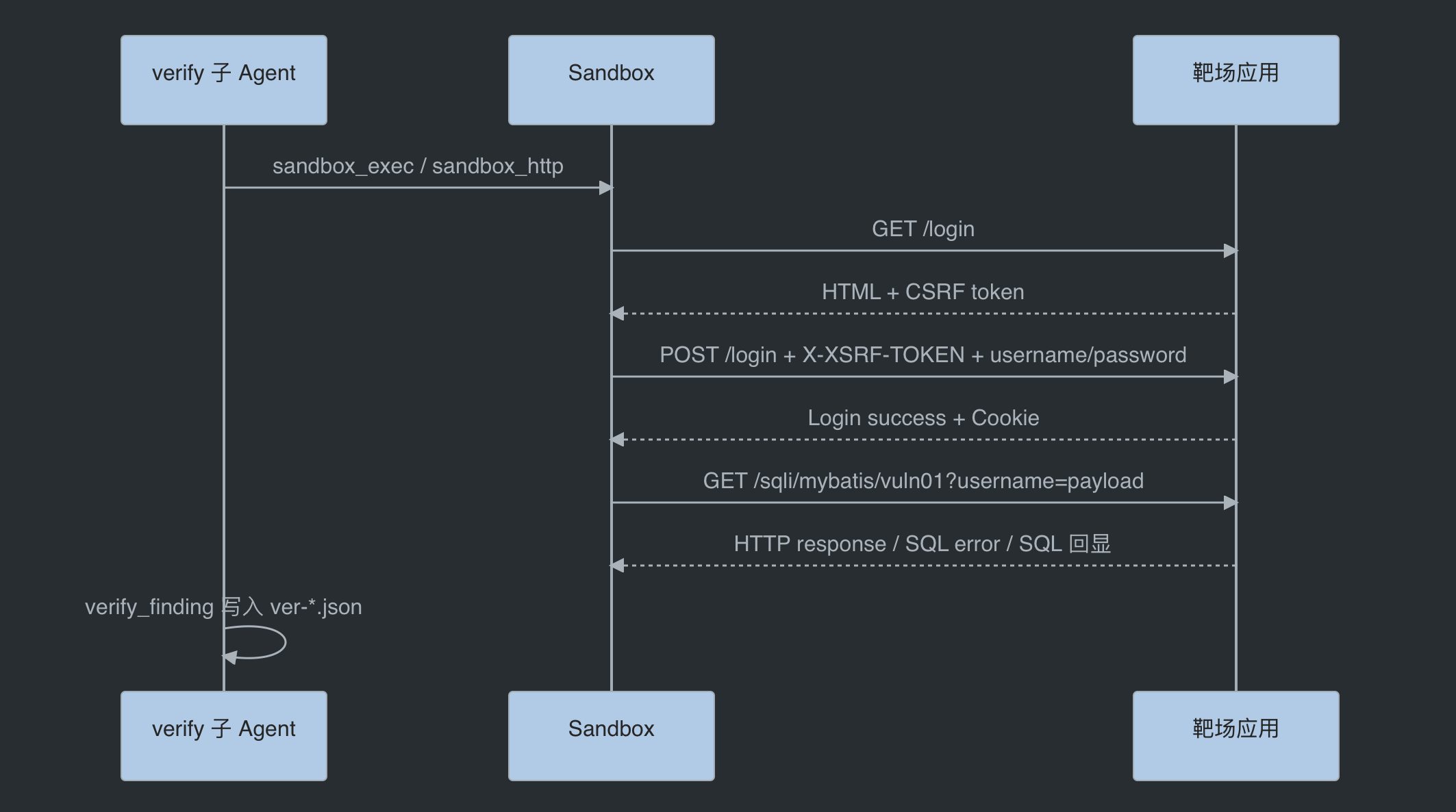
这一步非常贴近真实审计。很多扫描器能识别代码里的危险操作,但很少会继续自动完成登录、维护 Cookie、处理 CSRF,然后在靶场里发 PoC。
不过这类验证能力也有明确边界。它优先适用于靶场、测试环境和授权环境。真实业务系统中,SSO、MFA、验证码、权限分层、业务状态、异步任务、MQ、外部回连、对象存储、内网访问和 destructive payload 都可能让自动验证失败,或者需要人工提供上下文和安全边界。
| 场景 | 对 Agent 验证的影响 |
|---|---|
| SSO / MFA / 验证码 | 很难完全自动登录,需要人工提供会话或测试账号 |
| 权限分层 | 普通账号可达不代表高权限接口可验证 |
| 状态型漏洞 | 需要构造订单、审批、库存、任务等业务状态 |
| 异步任务 / MQ | HTTP 返回不一定能直接观察最终影响 |
| 生产环境 | 不能随意发送破坏性 payload |
| 外部依赖 | DNS、对象存储、回连、内网访问可能被网络策略限制 |
3、动态验证不只是“请求成功”,而是要解释结果
在这个靶场里,不同漏洞的验证结果也不一样。
MyBatis ${} 注入比较容易验证,因为错误回显里直接暴露了最终 SQL。例如 /sqli/mybatis/vuln01 的注入 payload 进入后,响应中能看到类似:
SQL: select * from users where username = 'joychou' or '1'='1'这说明 ${username} 不是参数化绑定,而是字面量替换,payload 已经进入 SQL 语句。
/sqli/mybatis/orderby/vuln03 也能通过 ORDER BY 注入验证:
SQL: select * from users order by id desc-- asc这里 -- 注释截断了后面拼接的 asc,说明 sort 参数直接进入了 ORDER BY 子句。
但 JDBC PreparedStatement 误用那条比较有意思:靶场数据库环境没有返回有效数据,接口多次请求都是 HTTP 200 且响应体为空。这个时候 Agent 没有强行写“动态利用成功”,而是把状态记录成 confirmed_by_pattern:
请求成功返回 200。源码确认 username 参数直接拼接到 SQL 中,然后传给 prepareStatement,参数化完全失效。沙箱环境 MySQL 可能未启动或无数据,导致结果集为空,但代码漏洞模式清晰可见。这点很重要。自动化验证不应该为了“看起来成功”而夸大结果。能动态确认的写 confirmed;环境限制导致无法完整回显,但源码和路径证据确凿的,写 confirmed_by_pattern;证据不足的,应该写 needs_review。
4、CodeOrion 的结果不是一段文字
一次审计最终会留下多层产物:
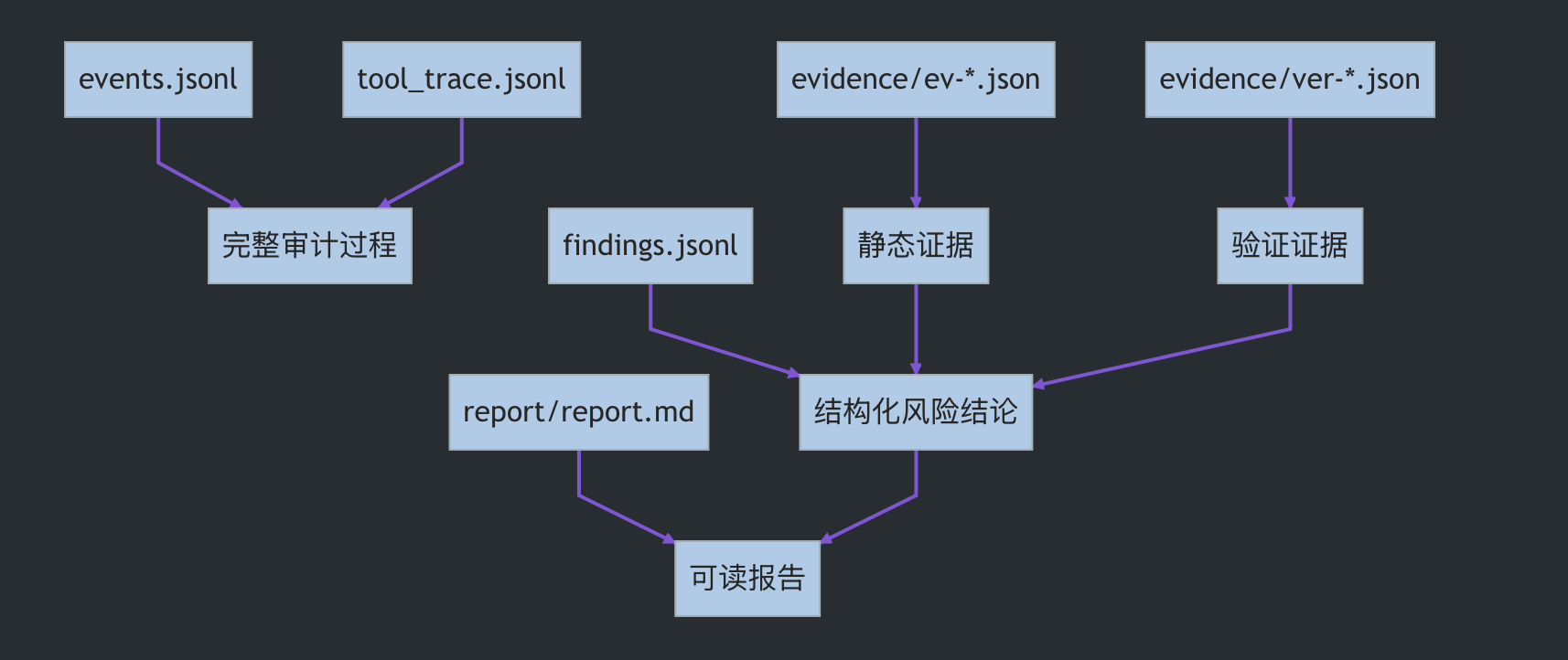
这和传统扫描器的一次性告警列表不一样。CodeOrion + codeorion-agent 输出的是一组可以复核的审计资产:
- 我为什么认为这个入口可疑
- 我调用了哪些 MCP 工具
- 我读了哪些源码和图谱事实
- 我登记了哪些证据
- 我构造了什么 PoC
- 沙箱返回了什么
- 最终结论为什么是
confirmed、confirmed_by_pattern或needs_review
这也是我希望它最终开源后能被持续改进的地方:每一次审计不是一个黑盒结论,而是一条可复盘、可调试、可改进的链路。
十、和传统 SAST 的区别
我不会说 CodeOrion 要替代 CodeQL、Semgrep、Joern 或成熟 SAST。传统 SAST 的规则、数据流、污点分析仍然非常重要。CodeOrion 更像是把这些结构事实变成 Agent 可以消费、追问和验证的审计底座。
| 传统 SAST 痛点 | CodeOrion + codeorion-agent 的处理方式 |
|---|---|
| 依赖硬编码规则,规则维护成本高 | CodeOrion 输出结构事实,Agent 按 Skill 和上下文动态组合查询 |
| 命中 source / sink 后误报多 | Agent 继续区分调用链可达、数据流可达、sanitizer、鉴权、配置和利用条件 |
| 很难深入第三方组件内部 | trace_dependency_calls 建模项目代码到依赖方法、依赖内部方法的路径 |
| 对业务逻辑漏洞覆盖弱 | Agent 可以结合代码图和上下文推理 IDOR、越权、认证绕过等逻辑问题 |
| 报告缺少可复核证据 | register_evidence 和 emit_finding 强制 evidence_refs |
| 大仓库直接读源码成本高 | 先用 MCP 查询结构化图谱,再按需读源码补证 |
| finding 难复现 | 支持 raw request、verify 子 Agent、sandbox PoC |
| 一次性扫描不可持续 | 保留 transcript、tool_trace、checkpoint、findings、report,支持 resume/finalize |
这个方向和行业趋势是一致的。Semgrep Multimodal 已经开始把 AI 用于复杂业务逻辑漏洞、自动研判、噪声过滤和修复建议。我的思路更进一步:不是先让规则扫描器吐告警,再让 AI 解释告警;而是从一开始就让 Agent 围绕代码图探索、取证和验证。
十一、一个更接近真实审计的例子
传统扫描器可能给出这样的结果:
发现危险函数 eval
发现用户输入 request.body
疑似 RCE但我更希望 CodeOrion + codeorion-agent 输出的是一条证据链:
POST /api/render
-> RenderController.render
-> TemplateService.compile
-> ThirdPartyTemplateEngine.evaluate
-> dependency_method: evaluateExpression
-> 危险操作: expression execution
证据:
ev-1: 入口追踪
ev-2: dependency call trace
ev-3: sanitizer 检查
ev-4: raw request / PoC前者是“像漏洞”,后者是“为什么这条链成立”。
这就是我认为 Agentic 代码审计(Agent 辅助代码审计)最重要的变化:从规则命中走向证据链推理。
十二、当前边界
开源项目必须讲清楚当前边界。
CodeOrion 当前已经具备稳定的 Tree-sitter CST 图、统一 IR、SQLite 存储、框架端点提取、依赖节点和跨边界追踪能力。符号表、CallGraph、DFG、CFG 等模块已经具备模型和查询入口,但完整语义图落库、跨语言精确数据流、复杂别名分析、框架深度建模仍然是后续增强方向。
也就是说,CodeOrion 当前最强的落地点不是“完整 CPG 实现”,也不是“完整替代传统 SAST 规则引擎”,而是把多语言源码解析结果、框架入口、依赖边界和查询工具统一成 Agent 可反复检索、扩展和取证的代码图底座。
后续我会继续强化:
- 更完整的语义边落库
- 更精确的跨文件符号解析
- 更强的框架和依赖注入建模
- 更完整的输入来源、危险操作、过滤逻辑候选生成
- 更好的组件内部调用链展开
- 更低成本的增量扫描
- 更适合安全审计的 Agent 证据视图
十三、结语
我对 CodeOrion 的定位很清楚:它不是传统 SAST 的简单替代品,也不是声称 LLM 可以直接完成白盒审计,而是一个面向 Agent 的代码图审计底座。
CodeOrion 负责把代码结构化,codeorion-agent 负责把结构事实变成审计行动。前者提供可查询的图,后者提供方法论、推理、证据、验证和报告。
组合起来之后,白盒审计不再只是“规则扫描”,而是变成一条可以追问、可以复核、可以验证的证据链。
CodeOrion 目前只是我个人的开源实验项目,并不是成熟的商业 SAST 产品。它的目标不是替代 CodeQL、Semgrep、Joern 这类成熟工具,而是探索一种更适合 AI Agent 使用的代码审计底座:先把代码结构化成可查询的事实,再让 Agent 围绕入口、调用链、依赖路径、证据和验证结果完成审计推理。
这个项目的大部分工程实现都有 AI 辅助参与,我主要负责整体思路、审计方法、功能设计和结果验证。也正因为如此,CodeOrion 还有很多不完整、不精确、不稳定的地方,但它代表的是一个我想持续验证的方向:让代码审计从“规则命中”进一步走向“证据链推理”。
十四、参考资料
- Joern Code Property Graph: https://docs.joern.io/code-property-graph/
- CodeQL About data flow analysis: https://codeql.github.com/docs/writing-codeql-queries/about-data-flow-analysis/
- Semgrep Taint analysis overview: https://docs.semgrep.dev/writing-rules/data-flow/taint-mode/overview
- OWASP Top 10:2021 A06 Vulnerable and Outdated Components: https://owasp.org/Top10/2021/A06_2021-Vulnerable_and_Outdated_Components/
- YASA: Scalable Multi-Language Taint Analysis on the Unified AST at Ant Group: https://arxiv.org/abs/2601.17390
- TraceLens: Question-Driven Debugging for Taint Flow Understanding: https://arxiv.org/abs/2508.07198
- QASecClaw: A Multi-Agent LLM Approach for False Positive Reduction in Static Application Security Testing: https://arxiv.org/abs/2605.01885
- SastBench: A Benchmark for Testing Agentic SAST Triage: https://arxiv.org/abs/2601.02941
- On the Security Blind Spots of Software Composition Analysis: https://arxiv.org/abs/2306.05534
- Hidden Dependencies and Component Variants in SBOM-Based Software Composition Analysis: https://arxiv.org/abs/2604.21278
扫描二维码推送至手机访问。
版权声明:本文由UzJu的安全屋发布,如需转载请注明出处。
SQL ERROR: ERROR 1105 (HY000): XPATH syntax error: '~root@localhost'
